Server mit NVIDIA H200 GPUs für KI- und HPC
Unvergleichliche Rechenleistung für generative KI, Simulationen und HPC-Workloads
Der Bedarf an Beschleunigung und Rechenleistung für generative KI, LLMs und HPC-Anwendungen erhöht die Ansprüche an die Hardware immens. Performance, Verfügbarkeit und Wirtschaftlichkeit stellen die wichtigsten Faktoren in der Auswahl der richtigen Hardware für die komplexesten Anwendungen dar. NVIDIA stellt sich der Herausforderung und bringt ihr neuestes GPU-Powerhouse auf den Markt - die NVIDIA H200 NVL GPU.
NVIDIA H200 – 141 Gigabyte HBM3e-Speicher und 4.8 TB/s Bandbreite
Die NVIDIA H200 NVL GPU ist die weltweit erste GPU mit 141 Gigabyte HBM3e-Speicher auf Basis der NVIDIA Hopper™-Architektur. Das bedeutet die nahezu doppelte Speicherkapazität des Vorgängers NVIDIA H100, gepaart mit der 1.4-fachen Speicherbandbreite von 4.8 Terabyte pro Sekunde. Der schnellere Speicher ermöglicht die Beschleunigung großer Sprachmodelle und die deutlich verbesserte Verarbeitung generativer KI-Prozesse. In Zahlen bedeutet das die doppelte Inferenzgeschwindigkeit bei der Verarbeitung von LLMs und eine bis zu 110-fach beschleunigte Ergebnisbereitstellung für Forschung, KI und Simulationen.
Als NVIDIA Elite Partner sind wir gerne Ihr Ansprechpartner, wenn es um leistungsstarke und hochverfügbare GPU Server Lösungen für Rechenzentren, Forschung und Industrie geht.
NVIDIA H200 NVL Details Beratung anfordern
Kategorien
Sortieren nach:

ASUS GPU Server ESC8000A-E13 4U AMD EPYC™
- 4 HE ASUS GPU Server Gehäuse
- 3200 Watt 2+2 / 3+1 redundant
- System on Chip
- 2x AMD EPYC™ 9005 Serie
- bis zu 3.0 TB DDR5 ECC Reg.
- über Erweiterungskarte + IPMI
- bis zu 8x NVIDIA H200 / H100 GPUs
- 8x 2.5" NVMe/SAS/SATA Hot-Swap
- M.2 optional über PCIe-Karte
- 3 Jahre Garantie inklusive
- Spare-Part Express Vorabaustausch

ASUS GPU Server ESC8000A-E13P 4U AMD EPYC™
- 4 HE ASUS GPU Server Gehäuse
- 3200 Watt 2+2 / 3+1 redundant
- System on Chip
- 2x AMD EPYC™ 9005 Serie
- bis zu 3.0 TB DDR5 ECC Reg.
- 2x 10 Gbit/s LAN + IPMI
- bis zu 8x NVIDIA H200 / H100 GPUs
- 8x 2.5" NVMe/SAS/SATA Hot-Swap
- M.2 optional über PCIe-Karte
- 3 Jahre Garantie inklusive
- Spare-Part Express Vorabaustausch

ASUS GPU Server RS521A-E12-RS24U AMD EPYC™ 9005 / 9004
- 2 HE ASUS Rack Server Gehäuse
- 2000 Watt Netzteil redundant
- System on Chip (SoC)
- 1x AMD EPYC™ 9005 / 9004 Serie
- bis zu 2.3 TB DDR5 ECC Reg.
- 2x 1 Gbit/s LAN + IPMI
- 4x PCIe 5.0 Zusatzkarte
- 20x 2.5" Hot-Swap NVMe, 2x SATA Option
- 2x M.2 Key M Port, PCIe 5.0 x4/SATA
- 3 Jahre Garantie inklusive
- Spare-Part Express Vorabaustausch

ASUS GPU Server RS521A-E12-RS24U AMD EPYC™
- 2 HE ASUS Rack Server Gehäuse
- 2000 Watt Netzteil redundant
- System on Chip (SoC)
- 1x AMD EPYC™ 9005 / 9004 Serie
- bis zu 2.3 TB DDR5 ECC Reg.
- 2x 1 Gbit/s LAN + IPMI
- bis zu 2x Dual-Slot-GPU
- 24x 2.5" Hot-Swap, 2x SATA Option
- 2x M.2 Key M Port, PCIe 4.0 x4/SATA
- 3 Jahre Garantie inklusive
- Spare-Part Express Vorabaustausch

ASUS GPU Server ESC4000A-E12 2U AMD EPYC
- 2 HE ASUS GPU Server Gehäuse
- 2600 Watt redundant
- System on Chip
- 1x AMD EPYC™ 9005 / 9004 Serie
- bis zu 3.0 TB DDR5 ECC Reg.
- 2x 1 Gbit/s LAN
- 2x NVIDIA H200 / 4x H100 GPU Support
- 6x Hot-Swap SAS/SATA (4x NVMe)
- nein
- 3 Jahre Garantie inklusive
- Spare-Part Express Vorabaustausch
Preisanfrage
Jetzt vorbestellen
High-End Datacenter GPU - NVIDIA H200
Die Datacenter GPU auf Basis der NVIDIA Hopper™-Architektur kommt mit einem Mehr-Instanzen-Grafikprozessor, der 4. Generation von Tensor-Kernen, der 3. Generation von RT-Kernen und einer FP32-Leistung von 67 TeraFLOPS.
Generative KI, LLM-Training und Inferenz Anwendungen profitieren von der FP8 Transformer Engine, einer Tensor-Leistung von über 3,9 PetaFLOPS und einem großem L2-Cache. Passend zu den Workloads ist die cloudnative Softwareplattform NVIDIA AI Enterprise beim Kauf inklusive!
141 Gigabyte HBM3e-Speicher sorgen für noch nie dagewesene Beschleunigung von HPC- und Inferenzworkloads.
Verbessern Sie die Medienbeschleunigung mit 7 Encode & Decode Engines, 7 JPEG-Dekodern und Unterstützung für AV1 Encode- & Decoding.
Bis zu vier H200 NVL GPUs können in einem GPU Server verbaut werden, und stellen in Kombination mit leistungsstarken Server Prozessoren eine enorme Rechenleistung für eine große Bandbreite an möglichen Workloads zur Verfügung.

Erreichen Sie Ihre Ziele schneller - mit weniger Kosten
1.9X schneller
1.6X schneller
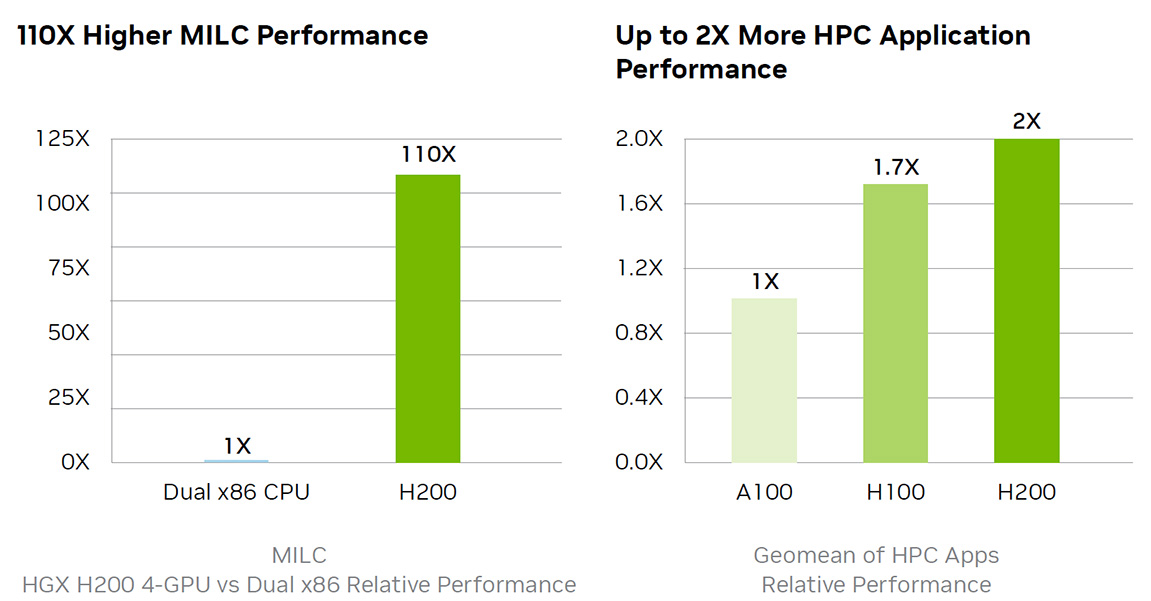
110X schneller
Erhöhte Performance für LLM-Inferenz
Die steigende Relevanz von LLMs für Unternehmen sorgt für bringt eine Vielzahl von zu erfüllenden Inferenzanforderungen mit sich. Um die Wirtschaftlichkeit von KI-Inferenzbeschleunigern zu gewährleisten, muss ein höchstmöglicher Durchsatz mit geringstmöglichen Gesamtbetriebskosten vereinbart werden.
Im Vergleich zum Vorgänger H100 verdoppelt die NVIDIA H200 NVL GPU die Inferenzgeschwindigkeit bei der Verarbeitung von großen Sprachmodellen wie zum Beispiel Llama2.
Mehr zur KI-Inferenzplattform von NVIDIA >
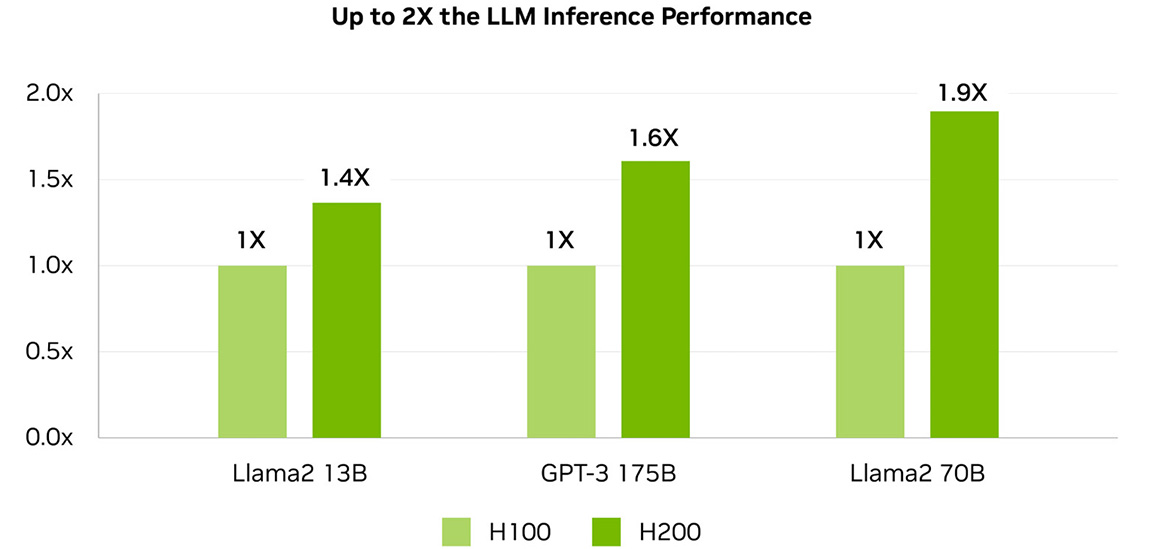
Mehr Speicherbandbreite für HPC-Anwendungen
Für die speicherintensivsten HPC-Anwendungen ist die Bandbreite von essenzieller Wichtigkeit, um schnellere Datenübertragungen zu ermöglichen und gleichzeitig Engpässe bei der hochkomplexen Verarbeitung zu reduzieren. Für Forschung, künstliche Intelligenz oder Simulationen – die H200 NVL GPU stellt mit ihren 4.8 TB/s Speicherbandbreite sicher, dass das Abrufen und die Bearbeitung von Daten effizient gestaltet wird – und so eine bis zu 110x schnellere Ergebnisbereitstellung ermöglicht.
Mehr über High-Performance Computing >
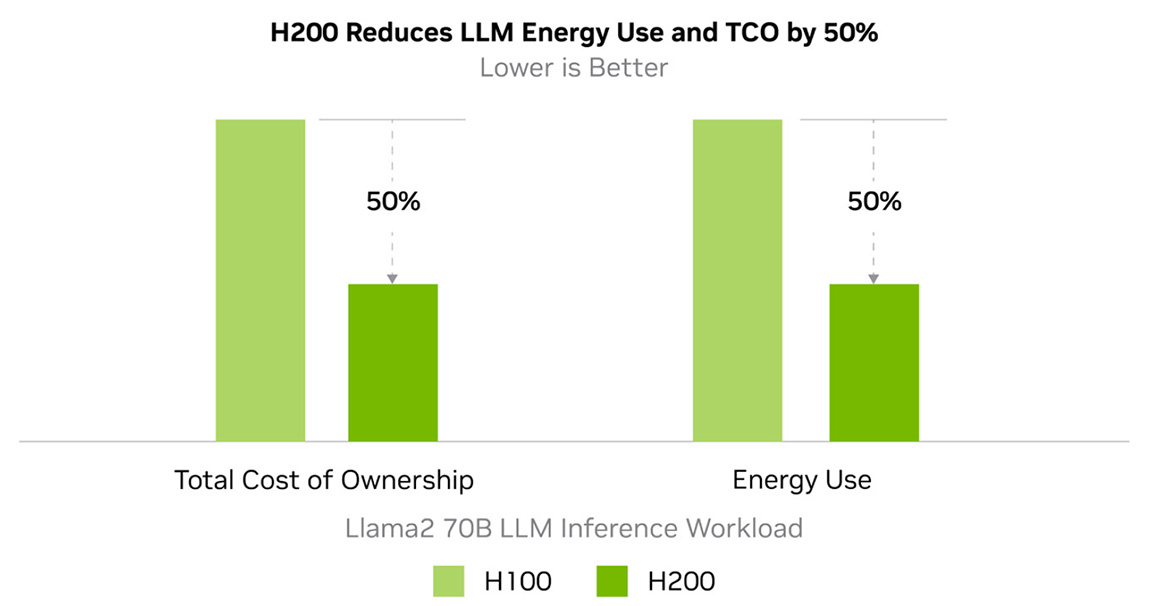
Weniger Energieverbrauch und Gesamtbetriebskosten
Die NVIDIA H200 NVL GPU bringt Energieeffizienz und Gesamtbetriebskosten auf ein neues Level. Mit dieser Technologie schafft es NVIDIA innerhalb des gleichen Leistungsprofils wie der H100 eine bislang unvergleichliche Leistung bereitzustellen. So wird die künstliche Intelligenz und das Supercomputing nicht nur schneller und effizienter, sondern auch nachhaltiger. Ein wirtschaftlicher Vorteil, der KI und Wissenschaft vorantreibt.
Mehr über nachhaltiges Computing >
NVIDIA H200 NVL vs NVIDIA H100 NVL vs NVIDIA HGX A100
Mehr Leistung für KI, HPC und Simulationen
| Modell | NVIDIA H200 NVL | NVIDIA H100 NVL | NVIDIA HGX A100 |
|---|---|---|---|
| Anwendungsgebiete | max. Performance für KI und HPC | starke Performance für generative KI | hochperformante Multi-Node KI |
| GPU-Architektur | NVIDIA Hopper | NVIDIA Hopper | NVIDIA Ampere |
| FP64 | 34 TFLOPS | 30 TFLOPS | 9,7 TFLOPS |
| FP32 | 67 TFLOPS | 60 TFLOPS | 19,5 TFLOPS |
| TF-32 Tensor Core | 989 TFLOPS | 835 TFLOPS | 312 TFLOPS |
| FB16/BF16 Tensor Core | 1979 TFLOPS | 1671 TFLOPS | 624 TFLOPS |
| FP8 Tensor Core | 3958 TFLOPS | 3341 TFLOPS | N/A |
| INT8 Tensor Core | 3958 TFLOPS | 3341 TFLOPS | 1248 TFLOPS |
| GPU Speicher | 141 GB HBM3e mit ECC | 94 GB HBM3 mit ECC | 80 GB HBM2e |
| GPU Speicher Bandbreite | 4,8 TB/s | 3,9 TB/s | 2039 GB/s |
| L2 Cache | 96 MB | 50 MB | 40 MB |
| Decoder | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 5 NVDEC 5 NVJPEG |
| Leistungsaufnahme | bis zu 600 Watt | bis zu 400 Watt | bis zu 400 Watt |
| Formfaktor | 2-Slot FHFL | 2-Slot FHFL | 8-Wege HGX |
| Verfügbarkeit | sehr lange Lieferzeit |
Jetzt Kontakt aufnehmen und von unseren GPU Server Experten beraten lassen
Kontaktieren Sie uns gern jederzeit.











