NVIDIA HGX™ Supercomputing
Entwickelt für KI, Simulationen & Datenanalysen
Das Training von KI-Modellen, komplexe Simulationen und die Analyse umfangreicher Datensätze erfordern meherere leistungsstarke GPUs mit extrem schnellen Verbindungen und einem vollständig beschleunigten Software-Stack. Die NVIDIA HGX™ Supercomputing-Plattform vereint die volle Leistung von NVIDIA B200 und NVIDIA H200 GPUs, NVIDIA NVLink™, NVIDIA Netzwerken und bietet zudem einen optimierten KI- und HPC-Software-Stack für maximale Anwendungsleistung. So können Ergebnisse wesentlich schneller und effizienter bereitgestellt werden.
Key Features der NVIDIA HGX™ Plattform
NVIDIA HGX™ Lösungen von ASUS und ASRock Rack
Als zertifizierter NVIDIA Elite Partner können wir Ihnen NVIDIA HGX™-Lösungen beider Hersteller anbieten. Sprechen Sie uns gerne an, unsere GPU-Server-Experten beraten Sie individuell und persönlich!
ASUS HGX™-Lösungen ASRock Rack HGX™-Lösungen Mehr erfahren
Kategorien
Sortieren nach:

ASRock Rack GPU Server Blackwell Ultra HGX B300 4U16X-TURIN2/DLC B300
- 4 HE Rack Server Gehäuse
- ZutaCore HyperCool Liquid Cooling
- 2x AMD EPYC 9005 CPU
- 8x NVIDIA HGX B300 GPU 279 GB HBM3e
- bis zu 6.0 TB DDR5-6400 RAM
- 10x 2.5" NVMe Festplatteneinschübe
- 2x M.2 PCIe 3.0 x2 / x4
- 8x NVIDIA ConnectX®-8 OSFP (800 Gb/s)
- 2x PCIe 5.0 x16 (PCIe-Switch)

ASRock Rack GPU Server Blackwell Ultra HGX B300 8U16X-TURIN2
- 8 HE Rack Server Gehäuse
- 2x AMD EPYC 9005 CPU
- 8x NVIDIA HGX B300 GPU 279 GB HBM3e
- bis zu 6.0 TB DDR5-6400 RAM
- 12x 2.5" NVMe Festplatteneinschübe
- 2x M.2 PCIe 3.0 x2 / x4
- 8x NVIDIA ConnectX®-8 OSFP (800 Gb/s)
- 4x PCIe 5.0 x16 Dual-Slot (PCIe-Switch, FHHL)

ASRock Rack GPU Server Blackwell Ultra HGX B300 8U16X-GNR2
- 8 HE Rack Server Gehäuse
- 2x Intel Xeon 6 CPU
- 8x NVIDIA HGX B300 GPU 279 GB HBM3e
- bis zu 8.0 TB DDR5-6400 RAM
- 12x 2.5" NVMe Festplatteneinschübe
- 2x M.2 PCIe 3.0 x2 / x4
- 8x NVIDIA ConnectX®-8 OSFP (800 Gb/s)
- 4x PCIe 5.0 x16 Dual-Slot (PCIe-Switch, FHHL)

GIGABYTE GPU Server HGX Blackwell B200 G893-ZD1
- 8 HE GIGABYTE Rack Server Gehäuse
- 6+6 3000 Watt Netzteile redundant
- System on Chip (SoC)
- 2x AMD EPYC™ 9005 Serie
- bis zu 3.0 TB DDR5 ECC Reg.
- 1x RJ-45 IPMI
- bis zu 12x PCIe 5.0 Zusatzkarte
- 8x 2.5" Hot-Swap NVMe
- 2x M.2 Key M Port, PCIe 3.0 x4/x1
- 3 Jahre Garantie inklusive
- Spare-Part Express Vorabaustausch

GIGABYTE GPU Server HGX Blackwell B200 G894-AD1
- 8 HE GIGABYTE Rack Server Gehäuse
- 6+6 3000 Watt Netzteile redundant
- System on Chip (SoC)
- 2x Intel Xeon 6900 Serie
- bis zu 2.3 TB DDR5 ECC Reg.
- 1x RJ-45 IPMI
- bis zu 12x PCIe 5.0 Zusatzkarte
- 8x 2.5" Hot-Swap NVMe
- 2x M.2 Key M Port, PCIe 5.0 x4/x2
- 3 Jahre Garantie inklusive
- Spare-Part Express Vorabaustausch

ASUS GPU Server HGX H200 ESC N8-E11V
- 7 HE Rack Server Gehäuse
- 2x Intel Xeon 8462Y+ CPU
- 8x NVIDIA HGX H200 GPU 141 GB HBM3e
- 2.0 TB DDR5-5600 RAM
- 5x 1.92 TB U.3 NVMe (9.6 TB)
- 8x NVIDIA ConnectX-7 400 Gb/s
Preisanfrage
Jetzt vorbestellen
End-to-End beschleunigte Computing-Plattform
Das NVIDIA HGX™ B200 kombiniert B200 Tensor Core GPUs mit Hochgeschwindigkeitsverbindungen, um die hochoptimierte und performante Server zu bilden. Konfigurationen von bis zu acht GPUs bieten eine Beschleunigung mit bis zu 1.4 Terabyte (TB) GPU-Speicher und einer aggregierten Speicherbandbreite von 14.4 Terabyte pro Sekunde (TB/s). Dies kombiniert mit 144 PetaFLOPS Leistung schafft eine beschleunigte leistungsstarke Scale-up-Serverplattform für KI und Hochleistungs-Computing (HPC).
Sowohl HGX™ B200 als auch HGX™ H200 beinhalten Netzwerklösungen mit Geschwindigkeiten von bis zu 400 Gigabit pro Sekunde (Gb/s) und nutzen NVIDIA Quantum-2 InfiniBand und Spectrum™-X Ethernet für optimierte KI-Leistung. HGX™ B200 und HGX™ H200 beinhalten auch NVIDIA® BlueField®-3 Data Processing Units (DPUs), um Cloud-Netzwerke, zusammensetzbaren Speicher, Zero-Trust-Sicherheit und GPU-Compute-Elastizität in hyperskalierbaren KI-Clouds zu ermöglichen.
1.4 TB aggregierter HBM3e-Speicher sorgen für außerordentliche Beschleunigung von HPC- und Inferenzworkloads.
Bis zu 8 B200 SXM GPUs können in einem HGX™ System verbaut werden, und stellen in Kombination mit zwei leistungsstarken AMD / Intel Server Prozessoren eine enorme Rechenleistung für eine große Bandbreite an möglichen Workloads zur Verfügung.
B200 Datenblatt Beratung anfordern
Deep Learning Inferenz: Leistung und Vielseitigkeit
KI löst eine Vielzahl von geschäftlichen Herausforderungen mit ebenso vielfältigen neuronalen Netzwerken. Ein KI-Inferenz-Beschleuniger muss nicht nur hohe Leistung erbringen, sondern auch die Vielseitigkeit bieten, die erforderlich ist, um diese Netzwerke an jedem Ort zu beschleunigen, an dem Kunden sie einsetzen möchten – vom Rechenzentrum bis hin zum Edge.
HGX™ B200 und HGX™ H200 erweitern NVIDIAs Martkplatzierung im Bereich Inferenz.
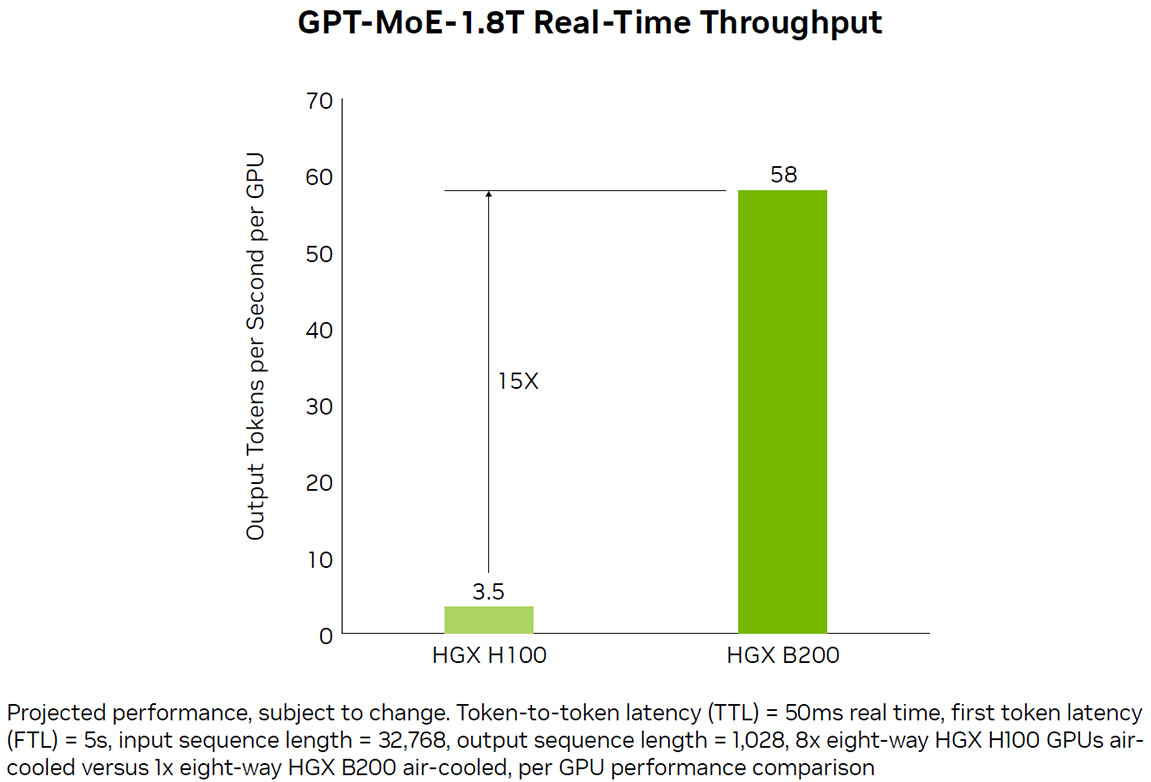
Echtzeit-Inferenz für die nächste Generation großer Sprachmodelle
Die HGX B200 erreicht eine bis zu 15-fach höhere Inferenzleistung im Vergleich zur vorherigen NVIDIA Hopper™-Generation für große Modelle wie GPT MoE 1.8T. Die zweite Generation der Transformer Engine nutzt die maßgeschneiderte Blackwell Tensor Core-Technologie in Kombination mit TensorRT™-LLM und den Innovationen des NVIDIA NeMo™-Frameworks, um die Inferenz für LLMs und Mixture-of-Experts (MoE)-Modelle zu beschleunigen.
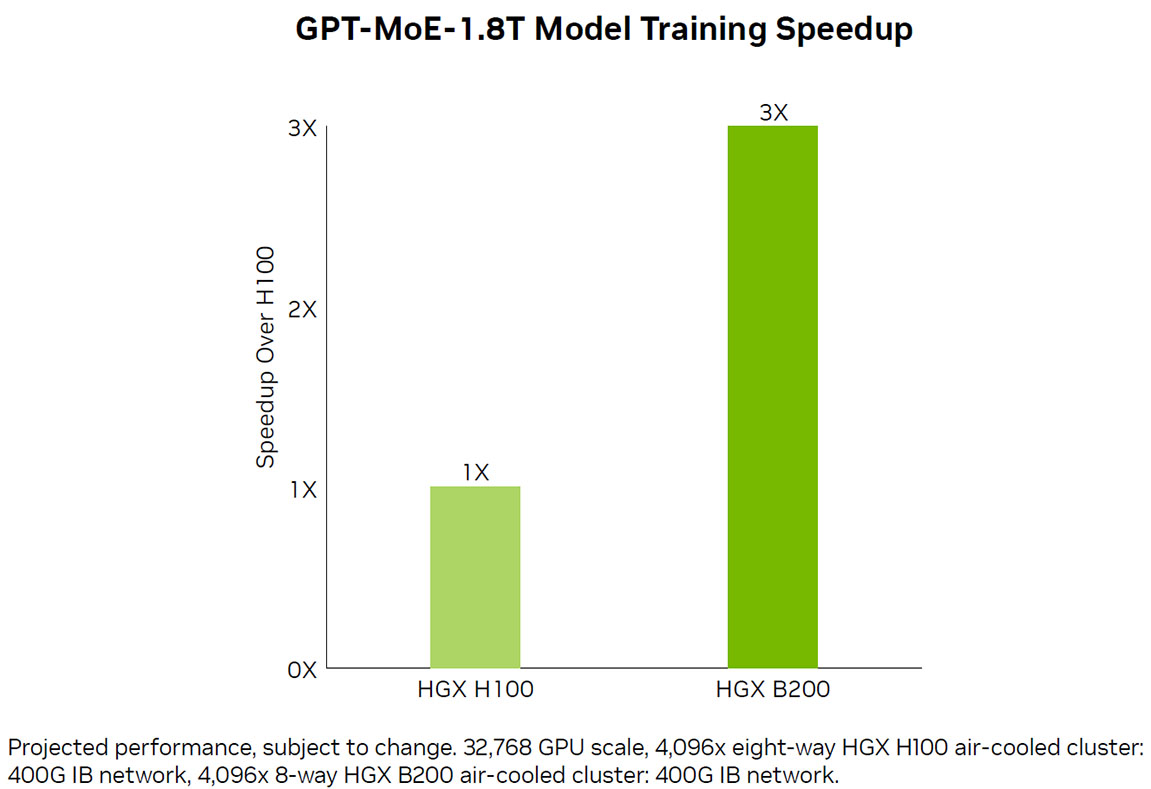
Next-Level Trainingsleistung
Die zweite Generation der Transformer Engine, die FP8 und neue Präzisionsformate unterstützt, ermöglicht ein beeindruckend 3-mal schnelleres Training für große Sprachmodelle wie GPT MoE 1.8T. Dieser Durchbruch wird durch die fünfte Generation von NVLink mit 1,8 TB/s GPU-zu-GPU-Verbindung, den NVSwitch-Chip, InfiniBand-Netzwerke und die NVIDIA Magnum IO-Software ergänzt. Zusammen gewährleisten diese Technologien eine effiziente Skalierbarkeit für Unternehmen und umfangreiche GPU-Computing-Cluster.
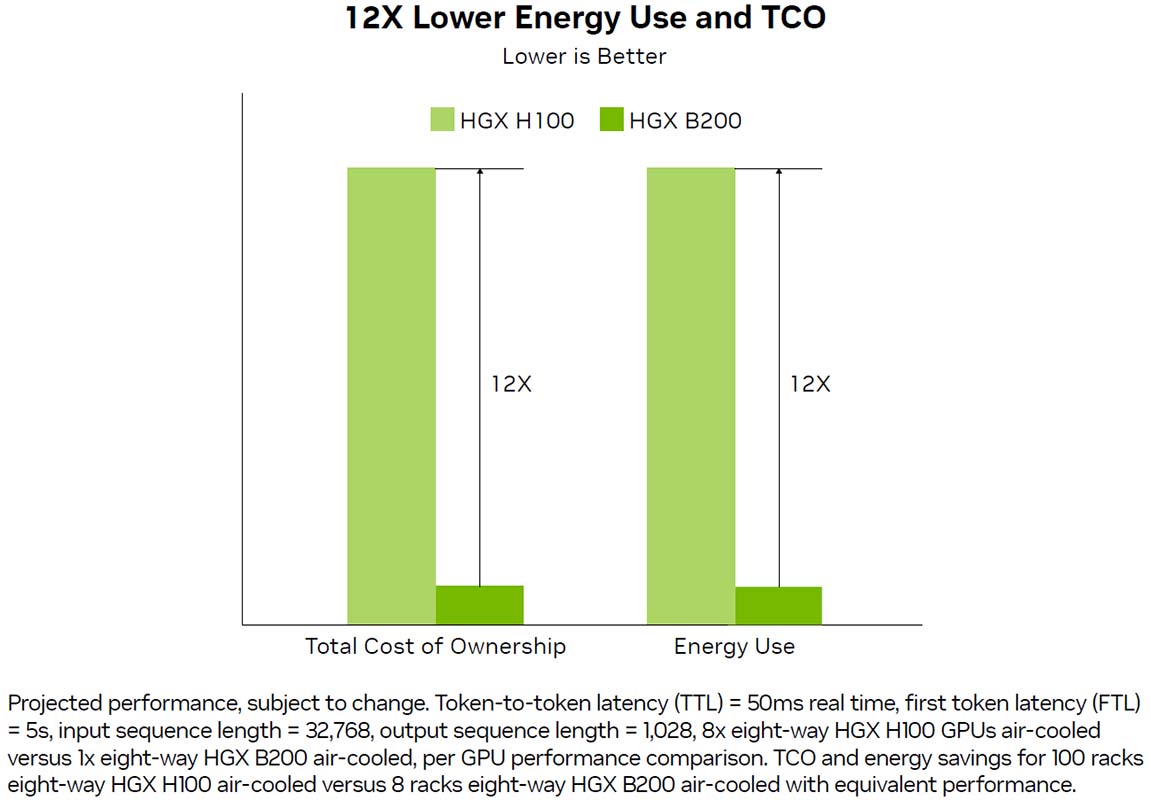
Nachhaltiges Computing
Durch die Einführung nachhaltiger Computing-Praktiken können Rechenzentren ihren CO₂-Fußabdruck und Energieverbrauch senken, während sie gleichzeitig ihre Wirtschaftlichkeit verbessern. Das Ziel des nachhaltigen Computings kann durch Effizienzsteigerungen mit beschleunigtem Computing auf Basis von HGX erreicht werden. Bei der Inferenzleistung für große Sprachmodelle (LLMs) steigert die HGX B200 die Energieeffizienz um das 12-fache und senkt die Kosten um das 12-fache im Vergleich zur Hopper-Generation.
Beschleunigung von HGX™ mit NVIDIA Networking
Das Rechenzentrum ist die neue Recheneinheit, und Netzwerke spielen eine integrale Rolle bei der Skalierung der Anwendungsleistung. In Kombination mit NVIDIA Quantum InfiniBand liefert HGX™ herausragende Leistung und Effizienz, was die volle Nutzung der Rechenressourcen sicherstellt.
Für KI-Cloud-Rechenzentren, die Ethernet einsetzen, wird HGX™ am besten mit der NVIDIA Spectrum-X Netzwerkplattform verwendet, die hohe KI-Leistung über Ethernet ermöglicht. Sie verfügt über Spectrum-X-Switches und BlueField-3 DPUs für optimale Ressourcennutzung und Leistungsisolation und liefert konsistente, vorhersehbare Ergebnisse für Tausende von gleichzeitigen KI-Aufgaben in jeder Größenordnung. Spectrum-X ermöglicht fortschrittliche Cloud-Mandantenfähigkeit und Zero-Trust-Sicherheit. Als Referenzdesign hat NVIDIA Israel-1 entwickelt, einen generativen Hyper-Scale KI-Supercomputer, der mit Dell PowerEdge XE9680 Servern auf Basis der NVIDIA HGX™ 8-GPU-Plattform, BlueField-3 DPUs und Spectrum-4 Switches gebaut wurde.
Technische Spezifikationen
| Modell | HGX B200 8-GPU | HGX H200 8-GPU | HGX H200 4-GPU |
|---|---|---|---|
| Formfaktor | 8x NVIDIA B200 SXM | 8x NVIDIA H200 SXM | 4x NVIDIA H200 SXM |
| FP8 Tensor Core | 72 PFLOPS | 32 PFLOPS | 16 PFLOPS |
| INT8 Tensor Core | 72 POPS | 32 POPS | 16 POPS |
| FP16/BFLOAT16 Tensor Core | 36 PFLOPS | 16 PFLOPS | 8 PFLOPS |
| TF32 Tensor Core | 18 PFLOPS | 8 PFLOPS | 4 PFLOPS |
| FP32 | 640 TFLOPS | 540 TFLOPS | 270 TFLOPS |
| FP64 | 320 TFLOPS | 270 TFLOPS | 140 TFLOPS |
| FP64 Tensor Core | 320 TFLOPS | 540 TFLOPS | 270 TFLOPS |
| Speicher | 1.4 TB HBM3e | 1.1 TB HBM3e | 564 GB HBM3e |
| Gesamte Aggregierte Bandbreite | 14.4 TB/s | 7.2 TB/s | 3.6 TB/s |
| NVLink | Fünfte Generation | Vierte Generation | Vierte Generation |
| NVSwitch | Vierte Generation | Dritte Generation | N/A |
| NVSwitch GPU-to-GPU Bandbreite | 1.8 TB/s | 900 GB/s | N/A |
NVIDIA HGX vs NVIDIA DGX - was sind die Unterschiede?
NVIDIA DGX ist eine schlüsselfertige KI-Plattform und ideal für schnellen Einstieg. NVIDIA HGX hingegen ist eine flexible Plattform für maßgeschneiderte Hochleistungsserver, was sie besonders attraktiv für Universitäten und Forschungsdienstleister macht.
NVIDIA HGX – Vorteile für Forschungsdienstleister und Universitäten
- Modularität & Anpassbarkeit: HGX erlaubt die Auswahl von CPU, Speicher, Netzwerk und Kühllösungen – ideal für Forschungseinrichtungen mit individuellen Anforderungen (z. B. GPU-Beschleuniger für Simulationen oder Deep Learning).
- Bessere Kosteneffizienz: Durch Integration in eigene Cluster oder Kooperation mit Systemintegratoren können Budgets optimal genutzt werden – besonders relevant bei öffentlichen Fördermitteln.
- Höhere Skalierbarkeit: Ermöglicht den Aufbau großer, verteilter HPC- oder KI-Cluster für verschiedene Institute oder Projekte innerhalb der Universität.
- Offenes Ökosystem: HGX-Plattformen werden von vielen OEMs unterstützt – das reduziert Abhängigkeiten von einzelnen Anbietern und erlaubt langfristige Systempflege und -erweiterung.
- Optimiert für gemischte Workloads: Von numerischer Simulation über Datenanalyse bis hin zu generativer KI – HGX-Systeme können flexibel auf verschiedene Forschungsfelder abgestimmt werden.
- Einbindung in bestehende Infrastrukturen: Ideal für Hochschulrechenzentren, da HGX-Komponenten in bestehende Serverracks und Kühlkonzepte integriert werden können.
NVIDIA DGX – Merkmale
- Vorkonfiguriertes Komplettsystem (inkl. GPUs, CPUs, Netzwerk, Software)
- Einfach in Betrieb zu nehmen („Plug-and-Play“)
- Begrenzte Anpassbarkeit
- Höherer Anschaffungspreis pro Recheneinheit
- Fokus auf Out-of-the-box-Performance
NVIDIA HGX vs NVIDIA DGX: Fazit
Für Forschungsdienstleister und Universitäten bietet NVIDIA HGX entscheidende Vorteile: hohe Flexibilität, bessere Skalierbarkeit, langfristige Investitionssicherheit und optimale Anpassbarkeit an vielfältige wissenschaftliche Workloads. Im Vergleich dazu ist DGX eher für klar umrissene, standardisierte KI-Anwendungsfälle ausgelegt.
Jetzt von unseren NVIDIA HGX Server Experten beraten lassen
Kontaktieren Sie uns gern jederzeit.











