Verfügbarkeit:
Die Lieferzeit für dieses Produkt beträgt ca. 7 Werktage ab Bestelleingang.
Für einen verbindlichen Liefertermin wenden Sie sich bitte direkt an unseren Vertrieb.
Weitere Informationen zu Versand und Zahlung
NVIDIA H200 NVL 141GB HBM3e PCIe 5.0 Data Center GPU(TCSH200NVLPCIE-PB)
Die GPU für KI und HPC
Herausragende Leistung für generative KI und High Performance Computing: Die NVIDIA H200 NVL GPU bietet unschlagbare Performance und Speicherkapazität. Durch die 141 Gigabyte HBM3e-Speicher, die in der H200 zum Einsatz kommen, werden sowohl große Sprachmodelle und generative KI beschleunigt als auch die komplexen Berechnungen von HPC-Workloads angetrieben.

Mehr Performance dank größerem und schnellerem HBM3e-Speicher
Basierend auf der NVIDIA Hopper™- Architektur ist die NVIDIA H200 die weltweit erste GPU mit 141 GB HBM3e-Speicher – fast die zweifache Kapazität des Vorgängers NVIDIA H100 – bei einer 1.4-fachen Speicherbandbreite von 4.8 Terabyte pro Sekunde. Der größere und schnellere HBM3e-Speicher beschleunigt große Sprachmodelle (LLMs) und die Prozesse generativer KI und bietet gleichzeitig eine deutlich verbesserte Energieeffizienz. So sorgt die NVIDIA H200 auch bei High Performance Computing Workloads für geringere Gesamtbetriebskosten.
Erhöhte Performance für LLM-Inferenz
Die steigende Relevanz von LLMs für Unternehmen sorgt für bringt eine Vielzahl von zu erfüllenden Inferenzanforderungen mit sich. Um die Wirtschaftlichkeit von KI-Inferenzbeschleunigern zu gewährleisten, muss ein höchstmöglicher Durchsatz mit geringstmöglichen Gesamtbetriebskosten vereinbart werden.
Im Vergleich zum Vorgänger H100 verdoppelt die NVIDIA H200 NVL GPU die Inferenzgeschwindigkeit bei der Verarbeitung von großen Sprachmodellen wie zum Beispiel Llama2.
Mehr zur KI-Inferenzplattform von NVIDIA >
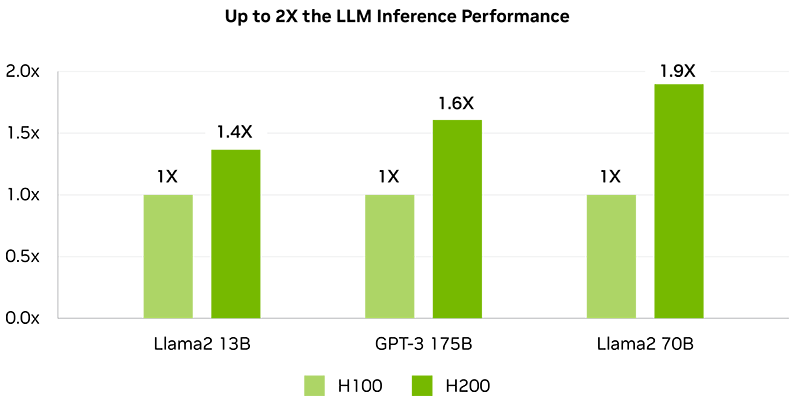
Llama2 13B: ISL 128, OSL 2K | Durchsatz | H100 SXM 1x GPU BS 64 | H200 SXM 1x GPU BS 128
GPT-3 175B: ISL 80, OSL 200 | x8 H100 SXM GPU BS 64 | x8 H200 SXM GPU BS 128
Llama2 70B: ISL 2K, OSL 128 | Durchsatz | H100 SXM 1x GPU BS 8 | H200 SXM 1x GPU BS 32
Mehr Speicherbandbreite für HPC-Anwendungen
Für die speicherintensivsten HPC-Anwendungen ist die Bandbreite von essenzieller Wichtigkeit, um schnellere Datenübertragungen zu ermöglichen und gleichzeitig Engpässe bei der hochkomplexen Verarbeitung zu reduzieren. Für Forschung, künstliche Intelligenz oder Simulationen – die H200 NVL GPU stellt mit ihren 4.8 TB/s Speicherbandbreite sicher, dass das Abrufen und die Bearbeitung von Daten effizient gestaltet wird – und so eine bis zu 110x schnellere Ergebnisbereitstellung ermöglicht.
Mehr über High-Performance Computing >
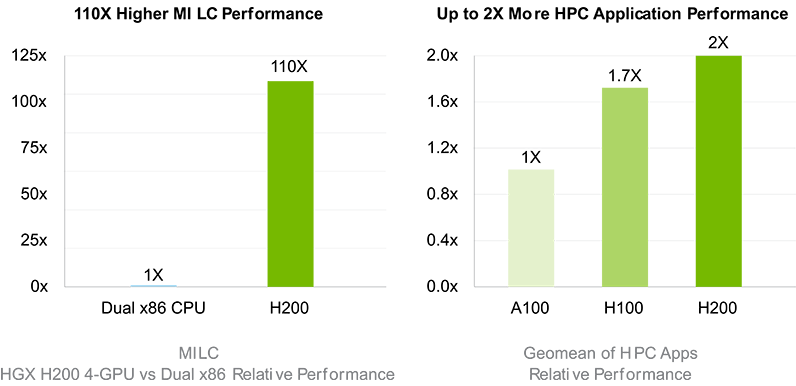
HPC MILC – Datensatz NERSC Apex Medium | HGX H200 4-GPU | Dual Sapphire Rapids 8480
HPC-Anwendungen – CP2K: Datensatz H2O-32-RI-dRPA-96points | GROMACS: Datensatz STMV | ICON: Datensatz r2b5 |
MILC: Datensatz NERSC Apex Medium | Chroma: Datensatz HMC Medium | Quantum Espresso: Datensatz AUSURF112 |
1 x H100 SXM | 1 H200 SXM
Weniger Energieverbrauch und Gesamtbetriebskosten
Die NVIDIA H200 NVL GPU bringt Energieeffizienz und Gesamtbetriebskosten auf ein neues Level. Mit dieser Technologie schafft es NVIDIA innerhalb des gleichen Leistungsprofils wie der H100 eine bislang unvergleichliche Leistung bereitzustellen. So wird die künstliche Intelligenz und das Supercomputing nicht nur schneller und effizienter, sondern auch nachhaltiger. Ein wirtschaftlicher Vorteil, der KI und Wissenschaft vorantreibt.
Mehr über nachhaltiges Computing >
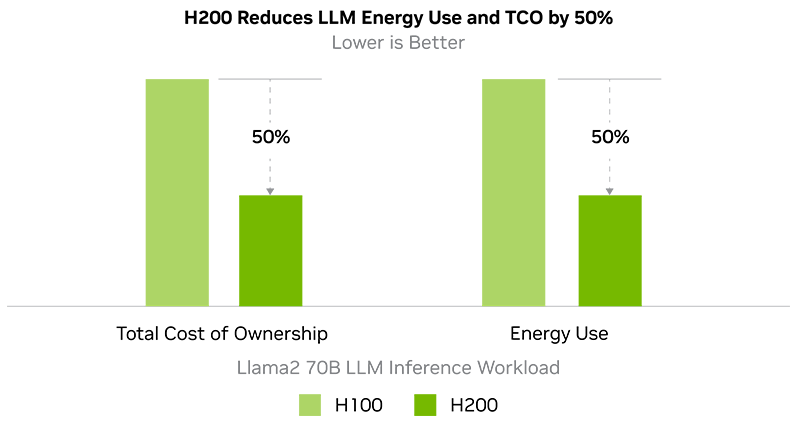
Llama2 70B: ISL 2K, OSL 128 | Durchsatz | H100 SXM 1x GPU BS 8 | H200 SXM 1x GPU BS 32
Mainstream-Enterprise-Server mit beschleunigter KI

Mit der NVIDIA H200 erhalten Sie die bestmögliche Performance auf kleinem Raum. So können Kunden mit eingeschränkten Platzverhältnissen in Rechenzentren von der größenunabhängigen Beschleunigung für KI- und HPC-Workloads profitieren. Mit der 1.5-fach gesteigerten Speichergröße und dem Upgrade auf HBM3e, sowie der 1.4-fachen Bandbreite von 4.8 TB/s gegenüber dem Vorgänger H100 können Sie Ihre LLMs innerhalb von wenigen Stunden optimieren und eine 1.8-mal schnellere LLM-Inferenz erreichen.
Technische Daten
| H200 NVL | ||
|---|---|---|
| FP64 | 34 teraFLOPS | |
| FP64-Tensor-Core | 67 teraFLOPS | |
| FP32 | 67 teraFLOPS | |
| TF32-Tensor-Core | 1.979* teraFLOPS | |
| BFLOAT16-Tensor-Core | 1.979* teraFLOPS | |
| FP16-Tensor-Core | 1.979* teraFLOPS | |
| FP8-Tensor-Core | 3.958* teraFLOPS | |
| INT8-Tensor-Core | 3.958* TOPS | |
| GPU-Speicher | 141 GB HBM3e | |
| GPU-Speicherbandbreite | 4.8 TB/s | |
| Decoder | 7 NVDEC / 7 JPEG | |
| Confidential Computing | Unterstützt | |
| Max. Thermal Design Power | bis zu 600W (konfigurierbar) | |
| Mehr-Instanzen-Grafikprozessoren | Bis zu 7 MIGs mit je 16.5 GB | |
| Formfaktor | PCIe | |
| Konnektivität | 2- oder 4-Way-NVIDIA NV-Link-Bridge: 900 GB/s PCIe Gen5: 128 GB/s | |
| Serveroptionen | NVIDIA MGX™ H200 NVL-Partner und NVIDIA-Certified Systems mit bis zu 8 GPUs | |
| NVIDIA AI Enterprise | Inbegriffen | |
Downloads | |
|---|---|
| Produktdatenblatt (PDF - 0.58MB) | |
Allgemein | |
|---|---|
| Hersteller | NVIDIA |
| Hersteller Artikelnummer | TCSH200NVLPCIE-PB |
| Hersteller Garantie (Monate) | 12 Mon. Hersteller Garantie |
| Verpackung | retail |
Erweiterungskarten | |
| Hostschnittstelle | PCI Express 5.0 x16 |
| Bauform kompatibel | full-height |
| Slot Belegung | Dual-Slot |
Arbeitsspeicher / Cache | |
| Speicher | 141 GB |
| Speicher Typ | HBM3e |
| Fehlerkorrektur | ECC |
Arbeitsspeicher Details | |
| Speicher Interface | 6.144 Bit |
| Speicher Bandbreite | 4800 GB/s |
Grafik- und GPU Karten | |
| Externe Anschlüsse | keine |
| Graphic APIs | OpenCL 3.0 |
| Compute APIs | CUDA, OpenCL |
| max. Displays simultan | 0 |
| Kühlung | passiv - für GPU Server geeignet [ohne Lüfter] |
| CUDA Kerne | 16896 CUDA Cores |
| Tensor Kerne | 528 Tensor Cores |
Abmessungen | |
| Breite | Dual Slot |
| Höhe | 111.15 mm |
| Tiefe | 267.7 mm |
Weiteres | |
| enthaltenes Zubehör | NVIDIA AI Enterprise |
Kontaktieren Sie uns gern jederzeit.











