Verfügbarkeit:
Kurzfristig verfügbar, Lieferzeit ca. 2-5 Werktage
Weitere Informationen zu Versand und Zahlung
NVIDIA H100 NVL 94GB HBM3 PCIe 5.0 Data Center GPU(TCSH100NVLPCIE-PB)
Ein Größenordnungssprung für beschleunigtes Computing
Mit dem NVIDIA H100 Tensor-Core-Grafikprozessor profitieren Sie von beispielloser Leistung, Skalierbarkeit und Sicherheit für jeden Workload. Mit dem NVIDIA NVLinkSwitch Switch-System können bis zu 256 H100 verbunden werden, um Exascale-Workloads zu beschleunigen, während die dedizierte Transformer Engine Billionen-Parameter-Sprachmodelle unterstützt. H100 greift auf Innovationen in der NVIDIA Hopper-Architektur zurück, um eine branchenführende Gesprächs-KI zu bieten und große Sprachmodelle bis zum 30-fachen im Vergleich zur Vorgeneration zu beschleunigen.
Transformations-KI-Training
NVIDIA H100-Grafikprozessoren verfügen über Tensor-Recheneinheiten der vierten Generation und die Transformer Engine mit FP8-Präzision, die bis zu 9-mal schnelleres Training im Vergleich zur vorherigen Generation für MoE-Modelle (Mixture of Experts) bietet. Die Kombination aus NVlink der vierten Generation, die eine GPU-zu-GPU-Verbindung von 600 Gigabyte pro Sekunde (GB/s) bietet, NVLINK Switch System, das die Kommunikation durch jeden Grafikprozessor über Knoten hinweg beschleunigt, PCIe der 5. Generation und NVIDIA Magnum IO-Software bietet effiziente Skalierbarkeit von kleinen Unternehmen bis hin zu riesigen, einheitlichen GPU-Clustern. Die Bereitstellung von H100-Grafikprozessoren im Rechenzentrumsmaßstab bietet hervorragende Leistung sowie die nächste Generation von Exascale High-Performance-Computing (HPC) und Billionen-Parameter-KI für alle Forscher.
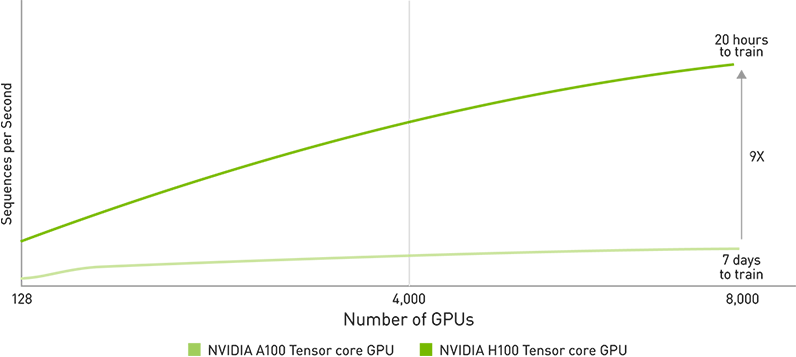
Echtzeit-Deep-Learning-Inferenz
KI löst eine Vielzahl von geschäftlichen Herausforderungen mit einer ebenso breiten Palette an neuronalen Netzen. Ein hervorragender KI-Inferenzbeschleuniger muss nicht nur höchste Leistung, sondern auch die Vielseitigkeit bieten, um diese Netzwerke zu beschleunigen. H100 erweitert die marktführende Position von NVIDIA bei Inferenz durch mehrere Fortschritte, die die Inferenz um das bis zu 30-Fache beschleunigen und die niedrigste Latenz bieten. Tensor-Recheneinheiten der vierten Generation beschleunigen alle Präzisionen, einschließlich FP64, TF32, FP32, FP16 sowie INT8, und die Transformer Engine verwendet FP8 und FP16 zusammen, um die Speicherauslastung zu reduzieren, die Leistung zu steigern und gleichzeitig die Genauigkeit für große Sprachmodelle aufrechtzuerhalten.
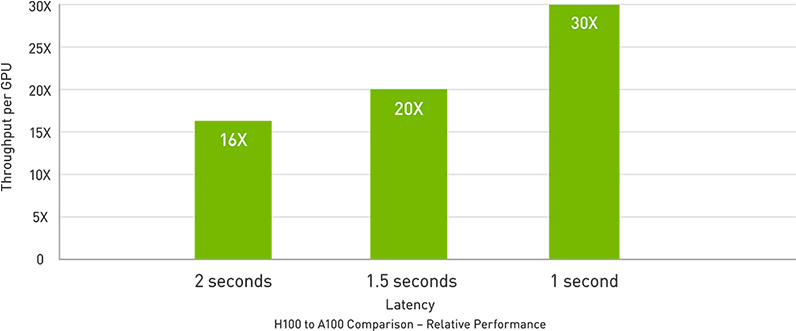
Exascale High-Performance Computing
Die NVIDIA-Rechenzentrumsplattform bietet konsistent Leistungssteigerungen, die über das Mooresche Gesetz hinausgehen. Die neuen bahnbrechenden KI-Funktionen von H100 verstärken die Leistungsfähigkeit von HPC und KI weiter, um für Wissenschaftler und Forscher, die an der Lösung der wichtigsten Herausforderungen der Welt arbeiten, die Zeit bis zum Entdecken zu verkürzen. H100 verdreifacht die Gleitkommaoperationen pro Sekunde (FLOPS) der Tensor Cores mit doppelter Genauigkeit und liefert 48 TeraFLOPS FP64-Computing für HPC. KI-gestützte HPC-Anwendungen können die TF32-Präzision von H100 nutzen, um einen PetaFLOP Durchsatz für Matrixmultiplikationsoperationen mit einfacher Genauigkeit zu erreichen, ohne Codeänderungen. H100 verfügt außerdem über DPX-Anweisungen, die bei dynamischen Programmieralgorithmen wie Smith-Waterman für die DNA-Sequenzausrichtung 7-mal mehr Leistung als NVIDIA A100 Tensor Core-GPUs und eine 40-fache Beschleunigung gegenüber herkömmlichen Servern mit Dual-Socket-CPUs allein bieten.
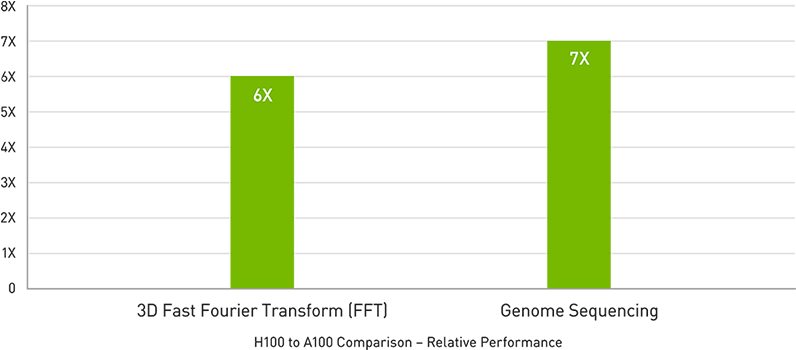
Datenanalysen
Datenanalysen nehmen bei der Entwicklung von KI-Anwendungen häufig den Großteil der Zeit in Anspruch. Da große Datensätze auf mehrere Server verteilt sind, werden Scale-Out-Lösungen mit reinen CPU-Standardservern durch fehlende skalierbare Rechenleistung ausgebremst. Beschleunigte Server mit H100 liefern die Rechenleistung – zusammen mit 2 Terabyte pro Sekunde (TB/s) Speicherbandbreite pro Grafikprozessor und Skalierbarkeit mit NVLink und NVSwitch–, um Datenanalysen mit hoher Leistung und Skalierung zur Unterstützung riesiger Datensätze zu bewältigen. In Kombination mit NVIDIA Quantum-2 Infiniband, der Magnum-IO-Software, dem grafikprozessorbeschleunigten Spark 3.0 und NVIDIA RAPIDS ist die NVIDIA-Rechenzentrum-Plattform dazu in der Lage, diese riesigen Workloads mit einem unvergleichlichen Maß an Leistung und Effizienz zu beschleunigen.
Unternehmensfähige Auslastung
IT-Manager versuchen, die Auslastung (sowohl Spitzen- als auch Durchschnittsauslastung) der Rechenressourcen im Rechenzentrum zu maximieren. Sie setzen häufig eine dynamische Neukonfiguration der Rechenleistung ein, um Ressourcen der richtigen Größe für die verwendeten Workloads zu erhalten. Die zweite Generation von Multi-Instance GPU (MIG) in H100 maximiert die Auslastung jeder GPU, indem sie sicher in bis zu sieben separate Instanzen partitioniert wird. Mit vertraulicher Computing-Unterstützung ermöglicht H100 eine sichere End-to-End-Nutzung mit mehreren Mandanten, ideal für Cloud-Service-Provider-Umgebungen (CSP). Dank H100 mit MIG können Infrastrukturmanager ihre GPU-beschleunigte Infrastruktur standardisieren und gleichzeitig die Flexibilität sichern, GPU-Ressourcen mit größerer Granularität bereitzustellen, um Entwicklern sicher die richtige Menge an beschleunigter Rechenleistung zur Verfügung zu stellen und die Nutzung aller ihrer GPU-Ressourcen zu optimieren.
NVIDIA Confidential Computing
Moderne vertrauliche Computing-Lösungen sind CPU-basiert, was für rechenintensive Workloads wie KI und HPC zu begrenzt ist. NVIDIA Confidential Computing ist eine integrierte Sicherheitsfunktion der NVIDIA Hopper-Architektur, die NVIDIA H100 zum weltweit ersten Beschleuniger mit vertraulichen Computing-Funktionen macht. Nutzer können die Vertraulichkeit und Integrität Ihrer Daten und Anwendungen schützen und gleichzeitig von der unübertroffenen Beschleunigung der H100-Grafikprozessoren für KI-Workloads profitieren. Es entsteht eine hardwarebasierte vertrauenswürdige Ausführungsumgebung (TEE), die den gesamten Workload schützt und isoliert. Dieser wird auf einer einzigen H100-GPU, mehreren H100-GPUs innerhalb eines Knotens oder einzelnen MIG-Instanzen ausgeführt. GPU-beschleunigte Anwendungen können im TEE unverändert ausgeführt werden und müssen nicht partitioniert werden. Nutzer können die Leistungsfähigkeit von NVIDIA-Software für KI und HPC mit der Sicherheit einer Hardware-Root-of-Trust-Anwendung kombinieren, die von NVIDIA Confidential Computing angeboten wird.
Konvergierter Beschleuniger H100 CNX von NVIDIA
NVIDIA H100 CNX kombiniert die Leistung des NVIDIA H100 mit den fortschrittlichen Netzwerkfunktionen der NVIDIA ConnectX-7 Smart Network Interface Card (SmartNIC) in einer einzigen, einzigartigen Plattform. Diese Konvergenz bietet unvergleichliche Leistung für GPU-gestützte Input/Output(IO)-intensive Workloads, z. B. verteiltes KI-Training im Unternehmens-Rechenzentrum und 5G-Verarbeitung am Edge.
NVIDIA Grace Hopper
Der Hopper Tensor-Core-Grafikprozessor wird die NVIDIA Grace Hopper CPU und GPU-Architektur unterstützen, die speziell für beschleunigtes Computing im Terabyte-Bereich entwickelt wurde und eine 10-mal höhere Leistung bei KI und HPC bei großen Modellen bietet. Die NVIDIA Grace-CPU nutzt die Flexibilität der Arm-Architektur, um eine CPU- und Serverarchitektur zu erstellen, die von Grund auf für beschleunigtes Computing entwickelt wurde. Die Hopper GPU wird mit der Grace CPU sowie der ultraschnellen Chip-zu-Chip-Verbindung von NVIDIA kombiniert und bietet eine Bandbreite von 600 GB/s. Dieses innovative Design bietet eine bis zu 30-mal höhere Gesamt-Systemspeicherbandbreite im Vergleich zu den schnellsten gegenwärtig verfügbaren Servern und eine bis zu 10-mal höhere Leistung für Anwendungen mit einem Datenvolumen von mehreren Terabytes.
Technische Daten
| H100 NVL | ||
|---|---|---|
| FP64 | 68 teraFLOPS | |
| FP64-Tensor-Core | 134 teraFLOPS | |
| FP32 | 134 teraFLOPS | |
| TF32-Tensor-Core | 1.979* teraFLOPS | |
| BFLOAT16-Tensor-Core | 3.958* teraFLOPS | |
| FP16-Tensor-Core | 3.958* teraFLOPS | |
| FP8-Tensor-Core | 7.916* teraFLOPS | |
| INT8-Tensor-Core | 7.916* TOPS | |
| GPU-Speicher | 188 GB HBM3 | |
| GPU-Speicherbandbreite | 7.8* TB/s | |
| Decoder | 14 NVDEC / 14 JPEG | |
| Max. Thermal Design Power | 2x 350-400W (konfigurierbar) | |
| Mehr-Instanzen-Grafikprozessoren | Bis zu 14 MIGs mit je 12 GB | |
| Formfaktor | 2x PCIe / 2x Dual-Slot mit Luftkühlung | |
| Konnektivität | NVLINK: 600 GB/s PCIe Gen5: 128 GB/s | |
| Serveroptionen | Partner und NVIDIA-Certified Systems mit 2-4 GPU-Paaren | |
Allgemein | |
|---|---|
| Hersteller | NVIDIA |
| Hersteller Artikelnummer | TCSH100NVLPCIE-PB |
| Hersteller Garantie (Monate) | 12 Mon. Hersteller Garantie |
| Verpackung | retail |
Erweiterungskarten | |
| Hostschnittstelle | PCI Express 5.0 x16 |
| Bauform kompatibel | full-height |
| Slot Belegung | Dual-Slot |
Arbeitsspeicher / Cache | |
| Speicher | 94 GB |
| Speicher Typ | HBM3 |
| Fehlerkorrektur | ECC |
Arbeitsspeicher Details | |
| Speicher Interface | 5.120 Bit |
| Speicher Bandbreite | 2048 GB/s |
Grafik- und GPU Karten | |
| Externe Anschlüsse | keine |
| Graphic APIs | OpenCL 3.0 |
| Compute APIs | CUDA, OpenCL |
| max. Displays simultan | 0 |
| Kühlung | passiv - für GPU Server geeignet [ohne Lüfter] |
| CUDA Kerne | 14592 CUDA Cores |
| Tensor Kerne | 456 Tensor Cores |
Abmessungen | |
| Breite | Dual Slot |
| Höhe | 111.15 mm |
| Tiefe | 267.7 mm |
Weiteres | |
| enthaltenes Zubehör | - |
Kontaktieren Sie uns gern jederzeit.











